About Recipes
A recipe is the most fundamental configuration element within the organization. A recipe:
- Is authored using Ruby, which is a programming language designed to read and behave in a predictable manner
- Is mostly a collection of resources, defined using patterns (resource names, attribute-value pairs, and actions); helper code is added around this using Ruby, when needed
- Must define everything that is required to configure part of a system
- Must be stored in a cookbook
- May be included in another recipe
- May use the results of a search query and read the contents of a data bag (including an encrypted data bag)
- May have a dependency on one (or more) recipes
- Must be added to a run-list before it can be used by Chef Infra Client
- Is always executed in the same order as listed in a run-list
Recipe Attributes
An attribute can be defined in a cookbook (or a recipe) and then used to
override the default settings on a node. When a cookbook is loaded
during a Chef Infra Client run, these attributes are compared to the
attributes that are already present on the node. Attributes that are
defined in attribute files are first loaded according to cookbook order.
For each cookbook, attributes in the default.rb file are loaded first,
and then additional attribute files (if present) are loaded in lexical
sort order. When the cookbook attributes take precedence over the
default attributes, Chef Infra Client applies those new settings and
values during a Chef Infra Client run on the node.
Note
Attribute Types
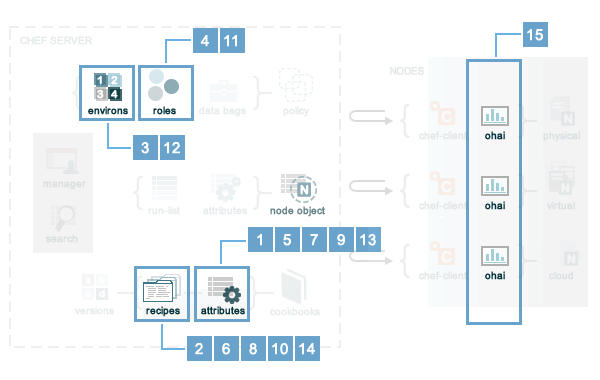
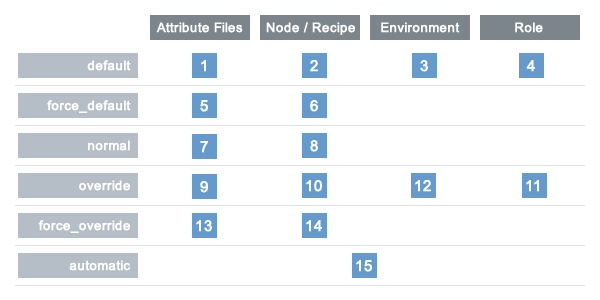
Chef Infra Client uses six types of attributes to determine the value that is applied to a node during a Chef Infra Client run. In addition, Chef Infra Client gathers attribute values from up to five locations. The combination of attribute types and sources makes up to 15 different competing values available during a Chef Infra Client run:
| Attribute Type | Description |
|---|---|
default | A default attribute is automatically reset at the start of every Chef
Infra Client run and has the lowest attribute precedence. Use default
attributes as often as possible in cookbooks. |
force_default | Use the force_default attribute to ensure that an attribute defined in
a cookbook (by an attribute file or by a recipe) takes precedence over a
default attribute set by a role or an environment. |
normal | A normal attribute is a setting that persists in the node object. A
normal attribute has a higher attribute precedence than a default
attribute. |
override | An override attribute is automatically reset at the start of every
Chef Infra Client run and has a higher attribute precedence than
default, force_default, and normal attributes. An override
attribute is most often specified in a recipe, but can be specified in
an attribute file, for a role, and/or for an environment. A cookbook
should be authored so that it uses override attributes only when
required. |
force_override | Use the force_override attribute to ensure that an attribute defined
in a cookbook (by an attribute file or by a recipe) takes precedence
over an override attribute set by a role or an environment. |
automatic | An automatic attribute contains data that is identified by Ohai at the
beginning of every Chef Infra Client run. An automatic attribute
cannot be modified and always has the highest attribute precedence. |
Attribute Persistence
All attributes except for normal attributes are reset at the beginning
of a Chef Infra Client run. Attributes set via chef-client -j with a
JSON file have normal precedence and are persisted between Chef Infra
Client runs. Chef Infra Client rebuilds these attributes using automatic
attributes collected by Ohai at the beginning of each Chef Infra Client
run, and then uses default and override attributes that are specified in
cookbooks, roles, environments, and Policyfiles. All attributes are then
merged and applied to the node according to attribute precedence. The
attributes that were applied to the node are saved to the Chef Infra
Server as part of the node object at the conclusion of each Chef Infra
Client run.
Attribute Precedence
Attributes are always applied by Chef Infra Client in the following order:
- A
defaultattribute located in a cookbook attribute file - A
defaultattribute located in a recipe - A
defaultattribute located in an environment - A
defaultattribute located in a role - A
force_defaultattribute located in a cookbook attribute file - A
force_defaultattribute located in a recipe - A
normalattribute located in a JSON file passed viachef-client -j - A
normalattribute located in a cookbook attribute file - A
normalattribute located in a recipe - An
overrideattribute located in a cookbook attribute file - An
overrideattribute located in a recipe - An
overrideattribute located in a role - An
overrideattribute located in an environment - A
force_overrideattribute located in a cookbook attribute file - A
force_overrideattribute located in a recipe - An
automaticattribute identified by Ohai at the start of a Chef Infra Client run
where the last attribute in the list is the one that is applied to the node.
Note
The attribute precedence order for roles and environments is reversed
for default and override attributes. The precedence order for
default attributes is environment, then role. The precedence order for
override attributes is role, then environment. Applying environment
override attributes after role override attributes allows the same
role to be used across multiple environments, yet ensuring that values
can be set that are specific to each environment (when required). For
example, the role for an application server may exist in all
environments, yet one environment may use a database server that is
different from other environments.
Attribute precedence, viewed from the same perspective as the overview diagram, where the numbers in the diagram match the order of attribute precedence:
Attribute precedence, when viewed as a table:
Blacklist Attributes
Warning
When attribute blacklist settings are used, any attribute defined in a
blacklist will not be saved and any attribute that is not defined in a
blacklist will be saved. Each attribute type is blacklisted
independently of the other attribute types. For example, if
automatic_attribute_blacklist defines attributes that will not be
saved, but normal_attribute_blacklist, default_attribute_blacklist,
and override_attribute_blacklist are not defined, then all normal
attributes, default attributes, and override attributes will be saved,
as well as the automatic attributes that were not specifically excluded
through blacklisting.
Attributes that should not be saved by a node may be blacklisted in the client.rb file. The blacklist is a Hash of keys that specify each attribute to be filtered out.
Attributes are blacklisted by attribute type, with each attribute type
being blacklisted independently. Each attribute type—automatic,
default, normal, and override—may define blacklists by using the
following settings in the client.rb file:
| Setting | Description |
|---|---|
automatic_attribute_blacklist | A hash that blacklists automatic attributes, preventing blacklisted attributes from being saved. For example: ['network/interfaces/eth0']. Default value: nil, all attributes are saved. If the array is empty, all attributes are saved. |
default_attribute_blacklist | A hash that blacklists default attributes, preventing blacklisted attributes from being saved. For example: ['filesystem/dev/disk0s2/size']. Default value: nil, all attributes are saved. If the array is empty, all attributes are saved. |
normal_attribute_blacklist | A hash that blacklists normal attributes, preventing blacklisted attributes from being saved. For example: ['filesystem/dev/disk0s2/size']. Default value: nil, all attributes are saved. If the array is empty, all attributes are saved. |
override_attribute_blacklist | A hash that blacklists override attributes, preventing blacklisted attributes from being saved. For example: ['map - autohome/size']. Default value: nil, all attributes are saved. If the array is empty, all attributes are saved. |
Warning
The recommended practice is to use only automatic_attribute_blacklist
for blacklisting attributes. This is primarily because automatic
attributes generate the most data, but also that normal, default, and
override attributes are typically much more important attributes and are
more likely to cause issues if they are blacklisted incorrectly.
For example, automatic attribute data similar to:
{
"filesystem" => {
"/dev/disk0s2" => {
"size" => "10mb"
},
"map - autohome" => {
"size" => "10mb"
}
},
"network" => {
"interfaces" => {
"eth0" => {...},
"eth1" => {...},
}
}
}
To blacklist the filesystem attributes and allow the other attributes
to be saved, update the client.rb file:
automatic_attribute_blacklist ['filesystem']
When a blacklist is defined, any attribute of that type that is not
specified in that attribute blacklist will be saved. So based on the
previous blacklist for automatic attributes, the filesystem and
map - autohome attributes will not be saved, but the network
attributes will.
For attributes that contain slashes (/) within the attribute value,
such as the filesystem attribute '/dev/diskos2', use an array. For
example:
automatic_attribute_blacklist [['filesystem','/dev/diskos2']]
Whitelist Attributes
Warning
When attribute whitelist settings are used, only the attributes defined
in a whitelist will be saved and any attribute that is not defined in a
whitelist will not be saved. Each attribute type is whitelisted
independently of the other attribute types. For example, if
automatic_attribute_whitelist defines attributes to be saved, but
normal_attribute_whitelist, default_attribute_whitelist, and
override_attribute_whitelist are not defined, then all normal
attributes, default attributes, and override attributes are saved, as
well as the automatic attributes that were specifically included through
whitelisting.
Attributes that should be saved by a node may be whitelisted in the client.rb file. The whitelist is a hash of keys that specifies each attribute to be saved.
Attributes are whitelisted by attribute type, with each attribute type
being whitelisted independently. Each attribute type—automatic,
default, normal, and override—may define whitelists by using the
following settings in the client.rb file:
| Setting | Description |
|---|---|
automatic_attribute_whitelist | A hash that whitelists automatic attributes, preventing non-whitelisted attributes from being saved. For example: ['network/interfaces/eth0']. Default value: nil, all attributes are saved. If the hash is empty, no attributes are saved. |
default_attribute_whitelist | A hash that whitelists default attributes, preventing non-whitelisted attributes from being saved. For example: ['filesystem/dev/disk0s2/size']. Default value: nil, all attributes are saved. If the hash is empty, no attributes are saved. |
normal_attribute_whitelist | A hash that whitelists normal attributes, preventing non-whitelisted attributes from being saved. For example: ['filesystem/dev/disk0s2/size']. Default value: nil, all attributes are saved. If the hash is empty, no attributes are saved. |
override_attribute_whitelist | A hash that whitelists override attributes, preventing non-whitelisted attributes from being saved. For example: ['map - autohome/size']. Default value: nil, all attributes are saved. If the hash is empty, no attributes are saved. |
Warning
The recommended practice is to only use automatic_attribute_whitelist
to whitelist attributes. This is primarily because automatic attributes
generate the most data, but also that normal, default, and override
attributes are typically much more important attributes and are more
likely to cause issues if they are whitelisted incorrectly.
For example, automatic attribute data similar to:
{
"filesystem" => {
"/dev/disk0s2" => {
"size" => "10mb"
},
"map - autohome" => {
"size" => "10mb"
}
},
"network" => {
"interfaces" => {
"eth0" => {...},
"eth1" => {...},
}
}
}
To whitelist the network attributes and prevent the other attributes
from being saved, update the client.rb file:
automatic_attribute_whitelist ['network/interfaces/']
When a whitelist is defined, any attribute of that type that is not
specified in that attribute whitelist will not be saved. So based on
the previous whitelist for automatic attributes, the filesystem and
map - autohome attributes will not be saved, but the network
attributes will.
Leave the value empty to prevent all attributes of that attribute type from being saved:
automatic_attribute_whitelist []
For attributes that contain slashes (/) within the attribute value,
such as the filesystem attribute '/dev/diskos2', use an array. For
example:
automatic_attribute_whitelist [['filesystem','/dev/diskos2']]
File Methods
Use the following methods within the attributes file for a cookbook or within a recipe. These methods correspond to the attribute type of the same name:
overridedefaultnormal(orset, wheresetis an alias fornormal)_unlessattribute?
Environment Variables
In UNIX, a process environment is a set of key-value pairs made available to a process. Programs expect their environment to contain information required for the program to run. The details of how these key-value pairs are accessed depends on the API of the language being used.
If processes is started by using the execute or script resources
(or any of the resources based on those two resources, such as
bash), use the environment attribute to alter the environment that
will be passed to the process.
bash 'env_test' do
code <<-EOF
echo $FOO
EOF
environment ({ 'FOO' => 'bar' })
end
The only environment being altered is the one being passed to the child process that is started by the bash resource. This will not affect the Chef Infra Client environment or any child processes.
Work with Recipes
The following sections show approaches to working with recipes.
Use Data Bags
Data bags store global variables as JSON data. Data bags are indexed for searching and can be loaded by a cookbook or accessed during a search.
The contents of a data bag can be loaded into a recipe. For example, a
data bag named apps and a data bag item named my_app:
{
"id": "my_app",
"repository": "git://github.com/company/my_app.git"
}
can be accessed in a recipe, like this:
my_bag = data_bag_item('apps', 'my_app')
The data bag item’s keys and values can be accessed with a Hash:
my_bag['repository'] #=> 'git://github.com/company/my_app.git'
Secret Keys
Encrypting a data bag item requires a secret key. A secret key can be created in any number of ways. For example, OpenSSL can be used to generate a random number, which can then be used as the secret key:
openssl rand -base64 512 | tr -d '\r\n' > encrypted_data_bag_secret
where encrypted_data_bag_secret is the name of the file which will
contain the secret key. For example, to create a secret key named
“my_secret_key”:
openssl rand -base64 512 | tr -d '\r\n' > my_secret_key
The tr command eliminates any trailing line feeds. Doing so avoids key
corruption when transferring the file between platforms with different
line endings.
Store Keys on Nodes
An encryption key can also be stored in an alternate file on the nodes
that need it and specify the path location to the file inside an
attribute; however, EncryptedDataBagItem.load expects to see the
actual secret as the third argument, rather than a path to the secret
file. In this case, you can use EncryptedDataBagItem.load_secret to
slurp the secret file contents and then pass them:
# inside your attribute file:
# default[:mysql][:secretpath] = 'C:\\chef\\any_secret_filename'
#
# inside your recipe:
# look for secret in file pointed to by mysql attribute :secretpath
mysql_secret = Chef::EncryptedDataBagItem.load_secret('#{node['mysql']['secretpath']}')
mysql_creds = Chef::EncryptedDataBagItem.load('passwords', 'mysql', mysql_secret)
mysql_creds['pass'] # will be decrypted
Assign Dependencies
If a cookbook has a dependency on a recipe that is located in another
cookbook, that dependency must be declared in the metadata.rb file for
that cookbook using the depends keyword.
Note
For example, if the following recipe is included in a cookbook named
my_app:
include_recipe 'apache2::mod_ssl'
Then the metadata.rb file for that cookbook would have:
depends 'apache2'
Include Recipes
A recipe can include one (or more) recipes from cookbooks by using the
include_recipe method. When a recipe is included, the resources found
in that recipe will be inserted (in the same exact order) at the point
where the include_recipe keyword is located.
The syntax for including a recipe is like this:
include_recipe 'recipe'
For example:
include_recipe 'apache2::mod_ssl'
Multiple recipes can be included within a recipe. For example:
include_recipe 'cookbook::setup'
include_recipe 'cookbook::install'
include_recipe 'cookbook::configure'
If a specific recipe is included more than once with the
include_recipe method or elsewhere in the run_list directly, only the
first instance is processed and subsequent inclusions are ignored.
Reload Attributes
Attributes sometimes depend on actions taken from within recipes, so it may be necessary to reload a given attribute from within a recipe. For example:
ruby_block 'some_code' do
block do
node.from_file(run_context.resolve_attribute('COOKBOOK_NAME', 'ATTR_FILE'))
end
action :nothing
end
Use Ruby
Anything that can be done with Ruby can be used within a recipe, such as
expressions (if, unless, etc.), case statements, loop statements,
arrays, hashes, and variables. In Ruby, the conditionals nil and
false are false; every other conditional is true.
Assign a value
A variable uses an equals sign (=) to assign a value.
To assign a value to a variable:
package_name = 'apache2'
Use Case Statement
A case statement can be used to compare an expression, and then execute the code that matches.
To select a package name based on platform:
package 'apache2' do
case node['platform']
when 'centos', 'redhat', 'fedora', 'suse'
package_name 'httpd'
when 'debian', 'ubuntu'
package_name 'apache2'
when 'arch'
package_name 'apache'
end
action :install
end
Check Conditions
An if expression can be used to check for conditions (true or false).
To check for condition only for Debian and Ubuntu platforms:
if platform?('debian', 'ubuntu')
# do something if node['platform'] is debian or ubuntu
else
# do other stuff
end
Execute Conditions
An unless expression can be used to execute code when a condition returns a false value (effectively, an unless expression is the opposite of an if statement).
To use an expression to execute when a condition returns a false value:
unless node['platform_version'] == '5.0'
# do stuff on everything but 5.0
end
Loop over Array
A loop statement is used to execute a block of code one (or more) times.
A loop statement is created when .each is added to an expression that
defines an array or a hash. An array is an integer-indexed collection of
objects. Each element in an array can be associated with and referred to
by an index.
To loop over an array of package names by platform:
['apache2', 'apache2-mpm'].each do |p|
package p
end
Loop over Hash
A hash is a collection of key-value pairs. Indexing for a hash is done
using arbitrary keys of any object (as opposed to the indexing done by
an array). The syntax for a hash is: key => "value".
To loop over a hash of gem package names:
{ 'fog' => '0.6.0', 'highline' => '1.6.0' }.each do |g, v|
gem_package g do
version v
end
end
Apply to Run-lists
A recipe must be assigned to a run-list using the appropriate name, as defined by the cookbook directory and namespace. For example, a cookbook directory has the following structure:
cookbooks/
apache2/
recipes/
default.rb
mod_ssl.rb
There are two recipes: a default recipe (that has the same name as the
cookbook) and a recipe named mod_ssl. The syntax that applies a recipe
to a run-list is similar to:
{
'run_list': [
'recipe[cookbook_name::default_recipe]',
'recipe[cookbook_name::recipe_name]'
]
}
where ::default_recipe is implied (and does not need to be specified).
On a node, these recipes can be assigned to a node’s run-list similar
to:
{
'run_list': [
'recipe[apache2]',
'recipe[apache2::mod_ssl]'
]
}
Chef Infra Server
Use knife to add a recipe to the run-list for a node. For example:
knife node run list add NODENAME "recipe[apache2]"
More than one recipe can be added:
% knife node run list add NODENAME "recipe[apache2],recipe[mysql],role[ssh]"
which creates a run-list similar to:
run_list:
recipe[apache2]
recipe[mysql]
role[ssh]
chef-solo
Use a JSON file to pass run-list details to chef-solo as long as the
cookbook in which the recipe is located is available to the system on
which chef-solo is running. For example, a file named dna.json
contains the following details:
{
"run_list": ["recipe[apache2]"]
}
To add the run-list to the node, enter the following:
sudo chef-solo -j /etc/chef/dna.json
Use Search Results
Search indexes allow queries to be made for any type of data that is
indexed by the Chef Infra Server, including data bags (and data bag
items), environments, nodes, and roles. A defined query syntax is used
to support search patterns like exact, wildcard, range, and fuzzy. A
search is a full-text query that can be done from several locations,
including from within a recipe, by using the search subcommand in
knife, the search method in the Recipe DSL, the search box in the Chef
management console, and by using the /search or /search/INDEX
endpoints in the Chef Infra Server API. The search engine is based on
Apache Solr and is run from the Chef Infra Server.
The results of a search query can be loaded into a recipe. For example, a very simple search query (in a recipe) might look like this:
search(:node, 'attribute:value')
A search query can be assigned to variables and then used elsewhere in a
recipe. For example, to search for all nodes that have a role assignment
named webserver, and then render a template which includes those role
assignments:
webservers = search(:node, 'role:webserver')
template '/tmp/list_of_webservers' do
source 'list_of_webservers.erb'
variables(webservers: webservers)
end
Use Tags
A tag is a custom description that is applied to a node. A tag, once applied, can be helpful when managing nodes using knife or when building recipes by providing alternate methods of grouping similar types of information.
Tags can be added and removed. Machines can be checked to see if they already have a specific tag. To use tags in your recipe simply add the following:
tag('mytag')
To test if a machine is tagged, add the following:
tagged?('mytag')
to return true or false. tagged? can also use an array as an
argument.
To remove a tag:
untag('mytag')
For example:
tag('machine')
if tagged?('machine')
Chef::Log.info("Hey I'm #{node[:tags]}")
end
untag('machine')
if not tagged?('machine')
Chef::Log.info('I has no tagz')
end
Will return something like this:
[Thu, 22 Jul 2010 18:01:45 +0000] INFO: Hey I'm machine
[Thu, 22 Jul 2010 18:01:45 +0000] INFO: I has no tagz
End Chef Infra Client Run
Sometimes it may be necessary to stop processing a recipe and/or stop processing the entire Chef Infra Client run. There are a few ways to do this:
- Use the
returnkeyword to stop processing a recipe based on a condition, but continue processing a Chef Infra Client run - Use the
raisekeyword to stop a Chef Infra Client run by triggering an unhandled exception - Use a
rescueblock in Ruby code - Use an exception handler
- Use
Chef::Application.fatal!to log a fatal message to the logger andSTDERR, and then stop a Chef Infra Client run
The following sections show various approaches to ending a Chef Infra Client run.
return Keyword
The return keyword can be used to stop processing a recipe based on a
condition, but continue processing a Chef Infra Client run. For example:
file '/tmp/name_of_file' do
action :create
end
return if platform?('windows')
package 'name_of_package' do
action :install
end
where platform?('windows') is the condition set on the return
keyword. When the condition is met, stop processing the recipe. This
approach is useful when there is no need to continue processing, such as
when a package cannot be installed. In this situation, it’s OK for a
recipe to stop processing.
fail/raise Keywords
In certain situations it may be useful to stop a Chef Infra Client run
entirely by using an unhandled exception. The raise and fail
keywords can be used to stop a Chef Infra Client run in both the compile
and execute phases.
Note
raise and fail behave the same way when triggering unhandled
exceptions and may be used interchangeably.Use these keywords in a recipe—but outside of any resource blocks—to trigger an unhandled exception during the compile phase. For example:
file '/tmp/name_of_file' do
action :create
end
raise "message" if platform?('windows')
package 'name_of_package' do
action :install
end
where platform?('windows') is the condition that will trigger the
unhandled exception.
Use these keywords in the ruby_block resource to trigger an unhandled exception during the execute phase. For example:
ruby_block "name" do
block do
# Ruby code with a condition, e.g. if ::File.exist?(::File.join(path, "/tmp"))
fail "message" # e.g. "Ordering issue with file path, expected foo"
end
end
Use these keywords in a class. For example:
class CustomError < StandardError; end
and then later on:
def custom_error
raise CustomError, "error message"
end
or:
def custom_error
fail CustomError, "error message"
end
Rescue Blocks
Since recipes are written in Ruby, they can be written to attempt to
handle error conditions using the rescue block.
For example:
begin
dater = data_bag_item(:basket, 'flowers')
rescue Net::HTTPClientException
# maybe some retry code here?
raise 'message_to_be_raised'
end
where data_bag_item makes an HTTP request to the Chef Infra Server to
get a data bag item named flowers. If there is a problem, the request
will return a Net::HTTPClientException. The rescue block can be used
to try to retry or otherwise handle the situation. If the rescue block
is unable to handle the situation, then the raise keyword is used to
specify the message to be raised.
Fatal Messages
A Chef Infra Client run is stopped after a fatal message is sent to the
logger and STDERR. For example:
Chef::Application.fatal!("log_message", error_code) if condition
where condition defines when a "log_message" and an error_code are
sent to the logger and STDERR, after which Chef Infra Client will
exit. The error_code itself is arbitrary and is assigned by the
individual who writes the code that triggers the fatal message.
Assigning an error code is optional, but they can be useful during log
file analysis.
This approach is used within Chef Infra Client itself to help ensure consistent messaging around certain behaviors. That said, this approach is not recommended for use within recipes and cookbooks and should only be used when the other approaches are not applicable.
Note
node.run_state
Use node.run_state to stash transient data during a Chef Infra Client
run. This data may be passed between resources, and then evaluated
during the execution phase. run_state is an empty Hash that is always
discarded at the end of a Chef Infra Client run.
For example, the following recipe will install the Apache web server, randomly choose PHP or Perl as the scripting language, and then install that scripting language:
package 'httpd' do
action :install
end
ruby_block 'randomly_choose_language' do
block do
if Random.rand > 0.5
node.run_state['scripting_language'] = 'php'
else
node.run_state['scripting_language'] = 'perl'
end
end
end
package 'scripting_language' do
package_name lazy { node.run_state['scripting_language'] }
action :install
end
where:
- The ruby_block resource declares a
blockof Ruby code that is run during the execution phase of a Chef Infra Client run - The
ifstatement randomly chooses PHP or Perl, saving the choice tonode.run_state['scripting_language'] - When the package resource has to install the package for the
scripting language, it looks up the scripting language and uses the
one defined in
node.run_state['scripting_language'] lazy {}ensures that the package resource evaluates this during the execution phase of a Chef Infra Client run (as opposed to during the compile phase)
When this recipe runs, Chef Infra Client will print something like the following:
* ruby_block[randomly_choose_language] action run
- execute the ruby block randomly_choose_language
* package[scripting_language] action install
- install version 5.3.3-27.el6_5 of package php